Installing SQL Server 2017 on Linux
The community Technology Preview (CTP) of SQL Server 2017 is now available on the Microsoft SQL Server Website. One of the most interesting features added is the Read-Scale Availability group option when using AlwaysOn. The Read-Scale Replica can be configured with or without High Availability by choosing the cluster manager option. It allows for scale-out read-only operations - meaning you can now create a replica only for read operations without the additional overhead and resources required when that read replica is part of a cluster (which is what provides the HA/DR for business continuity). Read-Scale replicas can be utilized on both Windows and Linux platforms, and can allow users to route directly to a read-only replica. You can read more about Read-Scale Availabilty Groups in the SQL Server Docs.
You can also read about some of the other cool new features added to SQL Server 2017 here.
To install SQL Server 2017 on Linux, the host server must have the following minimum requirements:

Since the Read-Scale Availability groups don't require a cluster, I will be installing and configuring SQL Server 2017 on Linux with a Read-Scale Replica without configuring a cluster. I used a combination of SQLCMD commands and SSMS to configure the environments.
You can find the scripts I used on my GitHub Repository
The high level steps are:
- Configure your hosts file on the Windows Server on which SSMS is installed and on the Linux Servers hosting your replicas:
On Windows, as an administrator, edit the file located at: C:\Windows\System32\drivers\etc\hosts
On RHEL/CentOS Linux, edit the /etc/hosts as sudo/root.
- Install SQL Server on all nodes
- You can have 1 primary and up to 8 secondary replicas, with a maximum of 2 synchronous-commit secondary replicas.
- Enable and Configure Always On Availability Groups(AG).
- Create the Availability Groups(AG) and add the secondary replicas to the AG.
Configure hosts file
Add the IP address and hostname of all replica host servers to the C:\Windows\System32\drivers\etc\hosts and /etc/hosts files.
Ping the hosts you added to ensure connectivity

INSTALL SQL SERVER

Confirm SQL Server was installed properly and open the default SQL Server port (1433) for access

Install any additional features/utilities such as SQL Server Agent and SQLCMD.
Repeat the steps above on all secondary nodes.
Once you're done with the installations, you should be able to connect using sqlcmd on the terminal of your Linux Host or via SSMS on your Windows Host.
CONFIGURE ALWAYSON
Enable AlwaysOn

After enabling AlwaysOn and restarting SQL Server, you can either use SQLCMD or SSMS to run the rest of the commands. I used a combination of both

After creating a login and user for the dbm_user - the database mirroring endpoint user, create a certificate that you will copy to the same location on all replica hosts. The certificate is used to authenticate communication between the mirroring endpoints

Copy the certificates to all replica nodes:

Connect to the secondary nodes and confirm that the files were copied and grant permissions allowing the mssql user access the certificate.

Create the Listener Endpoint
Create the mirroring endpoint. For this CTP version, the only listener IP allowed is 0.0.0.0
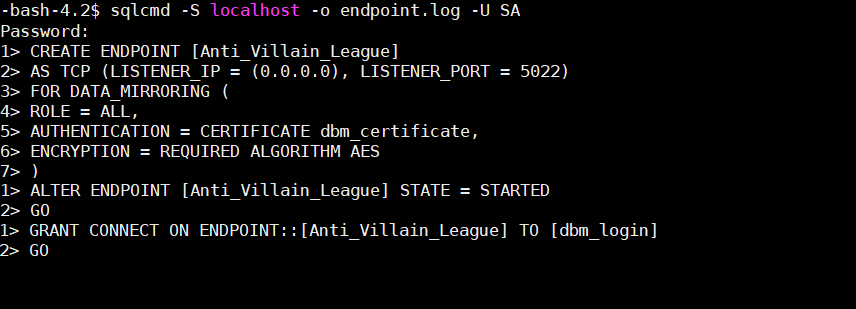
Open whatever port you used for the mirroring endpoint listener.

CREATE A DATABASE ON THE PRIMARY

To meet the prerequisites of databases that are added to an availability group, you must take a backup of the database - you can choose to take a dummy backup by backing up to 'nul'
CREATE THE AVAILABILITY GROUP
For this, I ran T-SQL via SSMS instead of SQLCMD.
Note: you could also use the New Availability Group Wizard GUI on SSMS

By selecting CLUSTER_TYPE=NONE and FAILOVER_MODE=MANUAL, you are configuring the Read_Scale replica without HA, but with Synchronous_commit AvailabilIty Mode - you can manually fail over to the read only replica without data loss.
You could also change the ALLOW_CONNECTIONS = READ-INTENT ONLY to configure the secondary replica as Read-Only.
Note: the SQL Server Installation docs suggest selecting FAILOVER_MODE=NONE, but that option does not exist. The only option is MANUAL for a Read-Scale configuration for this CTP. For a configuration with HA, you would select CLUSTER_TYPE=EXTERNAL for SQL Server on Linux.
Join secondary replicas to the AG

Add databases to the Availability Group

You can verify that the database was added to the Availability Group and connect to the readable secondary replicas to validate.

And there you have it - SQL Server on Linux with AlwaysOn Read-Scale replicas.